| Python3 与 C# 并发编程之~ 线程上篇 | 您所在的位置:网站首页 › thread join 和 detach › Python3 与 C# 并发编程之~ 线程上篇 |
Python3 与 C# 并发编程之~ 线程上篇
|
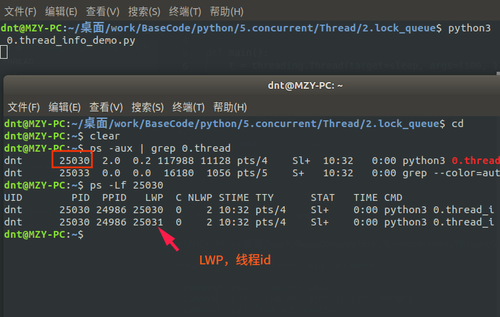
2.线程篇¶ 示例代码:https://github.com/lotapp/BaseCode/tree/master/python/5.concurrent/Thread 终于说道线程了,心酸啊,进程还有点东西下次接着聊,这周4天外出,所以注定发文少了+_+ 用过Java或者Net的重点都在线程这块,Python的重点其实在上篇,但线程自有其独到之处~比如资源共享(更轻量级) 这次采用循序渐进的方式讲解,先使用,再深入,然后扩展,最后来个案例,呃.呃.呃.先这样计划~欢迎纠正错误 2.1.入门篇¶官方文档:https://docs.python.org/3/library/threading.html 进程是由若干线程组成的(一个进程至少有一个线程) 2.1.1.线程案例¶用法和Process差不多,咱先看个案例:Thread(target=test, args=(i, )) import osfrom threading import Thread, current_thread def test(name): # current_thread()返回当前线程的实例 thread_name = current_thread().name # 获取线程名 print(f"[编号:{name}],ThreadName:{thread_name}\nPID:{os.getpid()},PPID:{os.getppid()}")def main(): t_list = [Thread(target=test, args=(i, )) for i in range(5)] for t in t_list: t.start() # 批量启动 for t in t_list: t.join() # 批量回收 # 主线程 print(f"[Main]ThreadName:{current_thread().name}\nPID:{os.getpid()},PPID:{os.getppid()}")if __name__ == '__main__': main()输出:(同一个进程ID) [编号:0],ThreadName:Thread-1 PID:20533,PPID:19830 [编号:1],ThreadName:Thread-2 PID:20533,PPID:19830 [编号:2],ThreadName:Thread-3 PID:20533,PPID:19830 [编号:3],ThreadName:Thread-4 PID:20533,PPID:19830 [编号:4],ThreadName:Thread-5 PID:20533,PPID:19830 [Main]ThreadName:MainThread PID:22636,PPID:19830注意一点:Python里面的线程是Posix Thread 2.1.2.指定线程名¶如果想给线程设置一个Div的名字呢?: from threading import Thread, current_threaddef test(): # current_thread()返回当前线程的实例 print(f"ThreadName:{current_thread().name}")def main(): t1 = Thread(target=test, name="小明") t2 = Thread(target=test) t1.start() t2.start() t1.join() t2.join() # 主线程 print(f"[Main],ThreadName:{current_thread().name}")if __name__ == '__main__': main()输出:(你指定有特点的名字,没指定就使用默认命令【联想古时候奴隶名字都是编号,主人赐名就有名了】) ThreadName:小明 ThreadName:Thread-1 [Main],ThreadName:MainThread类的方式创建线程 from threading import Threadclass MyThread(Thread): def __init__(self, name): # 设个坑,你可以自行研究下 super().__init__() # 放在后面就报错了 self.name = name def run(self): print(self.name)def main(): t = MyThread(name="小明") t.start() t.join()if __name__ == '__main__': main()输出:(和Thread初始化的name冲突了【变量名得注意哦】) 小明2.1.3.线程池案例¶from multiprocessing.dummy import Pool as ThreadPool, current_processdef test(i): # 本质调用了:threading.current_thread print(f"[编号{i}]{current_process().name}")def main(): p = ThreadPool() for i in range(5): p.apply_async(test, args=(i, )) p.close() p.join() print(f"{current_process().name}")if __name__ == '__main__': main()输出: [编号0]Thread-3 [编号1]Thread-4 [编号3]Thread-2 [编号2]Thread-1 [编号4]Thread-3 MainThread微微扩展一下¶对上面代码,项目里面一般都会这么优化:(并行这块线程后面会讲,不急) from multiprocessing.dummy import Pool as ThreadPool, current_processdef test(i): # 源码:current_process = threading.current_thread print(f"[编号{i}]{current_process().name}")def main(): p = ThreadPool() p.map_async(test, list(range(5))) p.close() p.join() print(f"{current_process().name}")if __name__ == '__main__': main()输出: [编号0]Thread-2 [编号1]Thread-4 [编号2]Thread-3 [编号4]Thread-2 [编号3]Thread-1 MainThread代码改动很小(循环换成了map)性能提升很明显(密集型操作) 2.1.4.其他扩展¶Thread初始化参数: daemon:是否为后台线程(主进程退出后台线程就退出了) Thread实例对象的方法: isAlive(): 返回线程是否活动的 getName(): 返回线程名 setName(): 设置线程名 isDaemon():是否为后台线程 setDaemon(True):设置后台线程 threading模块提供的一些方法: threading.currentThread(): 返回当前的线程实例 threading.enumerate(): 返回一个包含正在运行的线程List(线程启动后、结束前) threading.activeCount(): 返回正在运行的线程数量,与len(threading.enumerate())有相同的结果 看一个小案例: import timefrom threading import Thread, active_countdef test1(): print("test1") time.sleep(1) print("test1 ok")def test2(): print("test2") time.sleep(2) print("test2 ok")def main(): t1 = Thread(target=test1) t2 = Thread(target=test2, daemon=True) t1.start() t2.start() t1.join() print(active_count()) print(t1.is_alive) print(t2.is_alive) # t2.join() # 除非加这一句才等daemon线程,不然直接不管了if __name__ == '__main__': main()下次就以multiprocessing.dummy模块为例了,API和threading几乎一样,进行了一些并发的封装,性价比更高 2.2.加强篇¶ 其实以前的Linux中是没有线程这个概念的,Windows程序员经常使用线程,这一看~方便啊,然后可能是当时程序员偷懒了,就把进程模块改了改(这就是为什么之前说Linux下的多进程编程其实没有Win下那么“重量级”),弄了个精简版进程==>线程(内核是分不出进程和线程的,反正PCB个数都是一样) 多线程和多进程最大的不同在于,多进程中,同一个变量,各自有一份拷贝存在于每个进程中,互不影响,而多线程中,所有变量都由所有线程共享(全局变量和堆 ==> 线程间共享。进程的栈 ==> 线程平分而独占) 还记得通过current_thread()获取的线程信息吗?难道线程也没个id啥的?一起看看:(通过ps -Lf pid 来查看LWP)
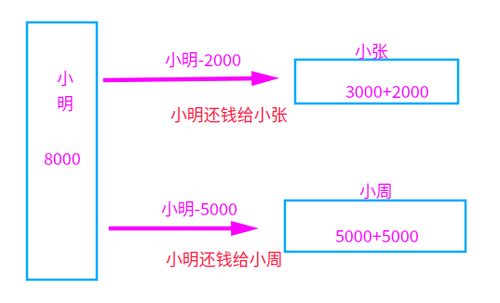
回顾:进程共享的内容:(回顾:http://www.cnblogs.com/dotnetcrazy/p/9363810.html) 代码(.text) 文件描述符(fd) 内存映射(mmap) 2.2.1.线程同步~互斥锁Lock¶线程之间共享数据的确方便,但是也容易出现数据混乱的现象,来看个例子: from multiprocessing.dummy import threadingnum = 0 # def global numdef test(i): print(f"子进程:{i}") global num for i in range(100000): num += 1def main(): p_list = [threading.Thread(target=test, args=(i, )) for i in range(5)] for i in p_list: i.start() for i in p_list: i.join() print(num) # 应该是500000,发生了数据混乱,结果少了很多if __name__ == '__main__': main()输出:(应该是500000,发生了数据混乱,只剩下358615) 子进程:0 子进程:1 子进程:2 子进程:3 子进程:4 452238Lock案例¶共享资源+CPU调度==>数据混乱==解决==>线程同步 这时候Lock就该上场了 互斥锁是实现线程同步最简单的一种方式,读写都加锁(读写都会串行) 先看看上面例子怎么解决调: from multiprocessing.dummy import threading, Locknum = 0 # def global numdef test(i, lock): print(f"子进程:{i}") global num for i in range(100000): with lock: num += 1def main(): lock = Lock() p_list = [threading.Thread(target=test, args=(i, lock)) for i in range(5)] for i in p_list: i.start() for i in p_list: i.join() print(num)if __name__ == '__main__': main()输出:time python3 1.thread.2.py 子进程:0 子进程:1 子进程:2 子进程:3 子进程:4 500000 real 0m2.846s user 0m1.897s sys 0m3.159s优化下¶lock设置为全局或者局部,性能几乎一样。循环换成map后性能有所提升(测试案例在Code中) from multiprocessing.dummy import Pool as ThreadPool, Locknum = 0 # def global numlock = Lock()def test(i): print(f"子进程:{i}") global num global lock for i in range(100000): with lock: num += 1def main(): p = ThreadPool() p.map_async(test, list(range(5))) p.close() p.join() print(num)if __name__ == '__main__': main()输出: time python3 1.thread.2.py 子进程:0 子进程:1 子进程:3 子进程:2 子进程:4 500000 real 0m2.468s user 0m1.667s sys 0m2.644s本来多线程访问共享资源的时候可以并行,加锁后就部分串行了(没获取到的线程就阻塞等了) 【项目中可以多次加锁,每次加锁只对修改部分加(尽量少的代码) 】(以后会说协程和Actor模型) 补充:以前都是这么写的,现在支持with托管了(有时候还会用到,所以了解下):【net是直接lock大括号包起来】 #### 以前写法:lock.acquire() # 获取锁try: num += 1finally: lock.release() # 释放锁#### 等价简写with lock: num += 1扩展知识:(GIL在扩展篇会详说) GIL的作用:多线程情况下必须存在资源的竞争,GIL是为了保证在解释器级别的线程唯一使用共享资源(cpu)。 同步锁的作用:为了保证解释器级别下的自己编写的程序唯一使用共享资源产生了同步锁 2.2.2.线程同步~可重入锁RLock¶看个场景:小明欠小张2000,欠小周5000,现在需要同时转账给他们:(规定:几次转账加几次锁) 小明啥也没管,直接撸起袖子就写Code了:(错误Code示意) from multiprocessing.dummy import Pool as ThreadPool, Lockxiaoming = 8000xiaozhang = 3000xiaozhou = 5000def test(lock): global xiaoming global xiaozhang global xiaozhou # 小明想一次搞定: with lock: # 小明转账2000给小张 xiaoming -= 2000 xiaozhang += 2000 with lock: # 小明转账5000给小周 xiaoming -= 5000 xiaozhou += 5000def main(): print(f"[还钱前]小明{xiaoming},小张{xiaozhang},小周{xiaozhou}") lock = Lock() p = ThreadPool() p.apply_async(test, args=(lock, )) p.close() p.join() print(f"[还钱后]小明{xiaoming},小张{xiaozhang},小周{xiaozhou}")if __name__ == '__main__': main()小明写完代码就出去了,这可把小周和小张等急了,打了N个电话来催,小明心想啥情况? 一看代码楞住了,改了改代码,轻轻松松把钱转出去了: from multiprocessing.dummy import Pool as ThreadPool, Lockxiaoming = 8000xiaozhang = 3000xiaozhou = 5000# 小明转账2000给小张def a_to_b(lock): global xiaoming global xiaozhang with lock: xiaoming -= 2000 xiaozhang += 2000# 小明转账5000给小周def a_to_c(lock): global xiaoming global xiaozhou with lock: xiaoming -= 5000 xiaozhou += 5000def main(): print(f"[还钱前]小明{xiaoming},小张{xiaozhang},小周{xiaozhou}") lock = Lock() p = ThreadPool() p.apply_async(a_to_b, args=(lock, )) p.apply_async(a_to_c, args=(lock, )) p.close() p.join() print(f"[还钱后]小明{xiaoming},小张{xiaozhang},小周{xiaozhou}")if __name__ == '__main__': main()输出: [还钱前]小明8000,小张3000,小周5000 [还钱后]小明1000,小张5000,小周10000就这么算了吗?不不不,不符合小明性格,于是小明研究了下,发现~还有个递归锁RLock呢,正好解决他的问题: from multiprocessing.dummy import Pool as ThreadPool, RLock # 就把这边换了下xiaoming = 8000xiaozhang = 3000xiaozhou = 5000def test(lock): global xiaoming global xiaozhang global xiaozhou # 小明想一次搞定: with lock: # 小明转账2000给小张 xiaoming -= 2000 xiaozhang += 2000 with lock: # 小明转账5000给小周 xiaoming -= 5000 xiaozhou += 5000def main(): print(f"[还钱前]小明{xiaoming},小张{xiaozhang},小周{xiaozhou}") lock = RLock() # 就把这边换了下 p = ThreadPool() p.apply_async(test, args=(lock, )) p.close() p.join() print(f"[还钱后]小明{xiaoming},小张{xiaozhang},小周{xiaozhou}")if __name__ == '__main__': main()RLock内部维护着一个Lock和一个counter变量,counter记录了acquire的次数,从而使得资源可以被多次require。直到一个线程所有的acquire都被release,其他的线程才能获得资源 2.2.3.死锁引入¶1.多次获取导致死锁¶小明想到了之前说的(互斥锁Lock读写都加锁)就把代码拆分研究了下: print("[开始]小明转账2000给小张")lock.acquire() # 获取锁xiaoming -= 2000xiaozhang += 2000print("[开始]小明转账5000给小周")lock.acquire() # 获取锁(互斥锁第二次加锁)xiaoming -= 5000xiaozhou += 5000lock.release() # 释放锁print("[结束]小明转账5000给小周")lock.release() # 释放锁print("[开始]小明转账2000给小张")输出发现:(第二次加锁的时候,变成阻塞等了【死锁】) [还钱前]小明8000,小张3000,小周5000 [开始]小明转账2000给小张 [开始]小明转账5000给小周这种方式,Python提供的RLock就可以解决了 2.常见的死锁¶看个场景:小明和小张需要流水帐,经常互刷~小明给小张转账1000,小张给小明转账1000 一般来说,有几个共享资源就加几把锁(小张、小明就是两个共享资源,所以需要两把Lock) 先描述下然后再看代码: 正常流程 小明给小张转1000:小明自己先加个锁==>小明-1000==>获取小张的锁==>小张+1000==>转账完毕 死锁情况 小明给小张转1000:小明自己先加个锁==>小明-1000==>准备获取小张的锁。可是这时候小张准备转账给小明,已经把自己的锁获取了,在等小明的锁(两个人相互等,于是就一直死锁了) 代码模拟一下过程: from time import sleepfrom multiprocessing.dummy import Pool as ThreadPool, Lockxiaoming = 5000xiaozhang = 8000m_lock = Lock() # 小明的锁z_lock = Lock() # 小张的锁# 小明转账1000给小张def a_to_b(): global xiaoming global xiaozhang global m_lock global z_lock with m_lock: xiaoming -= 1000 sleep(0.01) with z_lock: xiaozhang += 1000# 小张转账1000给小明def b_to_a(): global xiaoming global xiaozhang global m_lock global z_lock with z_lock: xiaozhang -= 1000 sleep(0.01) with m_lock: xiaoming += 1000def main(): print(f"[还钱前]小明{xiaoming},小张{xiaozhang}") p = ThreadPool() p.apply_async(a_to_b) p.apply_async(b_to_a) p.close() p.join() print(f"[还钱后]小明{xiaoming},小张{xiaozhang}")if __name__ == '__main__': main()输出:(卡在这边了) [转账前]小明5000,小张8000项目中像这类的情况,一般都是这几种解决方法:(还有其他解决方案,后面会继续说) 按指定顺序去访问共享资源 trylock的重试机制(Lock(False)) 在访问其他锁的时候,先把自己锁解了 得不到全部锁就先放弃已经获取的资源 比如上面的情况,我们如果规定,不管是谁先转账,先从小明开始,然后再小张,那么就没问题了。或者谁钱多就谁(权重高的优先) from time import sleepfrom multiprocessing.dummy import Pool as ThreadPool, Lockxiaoming = 5000xiaozhang = 8000m_lock = Lock() # 小明的锁z_lock = Lock() # 小张的锁# 小明转账1000给小张def a_to_b(): global xiaoming global xiaozhang global m_lock global z_lock # 以上次代码为例,这边只修改了这块 with z_lock: # 小张权重高,大家都先获取小张的锁 xiaozhang += 1000 sleep(0.01) with m_lock: xiaoming -= 1000# 小张转账1000给小明def b_to_a(): global xiaoming global xiaozhang global m_lock global z_lock with z_lock: xiaozhang -= 1000 sleep(0.01) with m_lock: xiaoming += 1000def main(): print(f"[转账前]小明{xiaoming},小张{xiaozhang}") p = ThreadPool() p.apply_async(a_to_b) p.apply_async(b_to_a) p.close() p.join() print(f"[转账后]小明{xiaoming},小张{xiaozhang}")if __name__ == '__main__': main()输出: [转账前]小明5000,小张8000 [转账后]小明5000,小张80002.2.4.线程同步~条件变量Condition¶条件变量一般都不是锁,只能能阻塞线程,从而减少不必要的竞争,Python内置了RLock(不指定就是RLock) 看看源码: class Condition: """ 实现条件变量的类。 条件变量允许一个或多个线程等到另一个线程通知它们为止 如果给出了lock参数而不是None,那必须是Lock或RLock对象作底层锁。 否则,一个新的RLock对象被创建并用作底层锁。 """ def __init__(self, lock=None): if lock is None: lock = RLock() self._lock = lock # 设置lock的acquire()和release()方法 self.acquire = lock.acquire self.release = lock.release再看看可不可以进行with托管:(支持) def __enter__(self): return self._lock.__enter__()def __exit__(self, *args): return self._lock.__exit__(*args)看个生产消费者的简单例子:(生产完就通知消费者) from multiprocessing.dummy import Pool as ThreadPool, Conditions_list = []con = Condition()def Shop(i): global con global s_list # 加锁保护共享资源 for x in range(5): with con: s_list.append(x) print(f"[生产者{i}]生产商品{x}") con.notify_all() # 通知消费者有货了def User(i): global con global s_list while True: with con: if s_list: print(f"列表商品:{s_list}") name = s_list.pop() # 消费商品 print(f"[消费者{i}]消费商品{name}") print(f"列表剩余:{s_list}") else: con.wait()def main(): p = ThreadPool() # 两个生产者 p.map_async(Shop, range(2)) # 五个消费者 p.map_async(User, range(5)) p.close() p.join()if __name__ == '__main__': main()输出:(list之类的虽然可以不加global标示,但是为了后期维护方便,建议加上) [生产者0]生产商品0 [生产者0]生产商品1 列表商品:[0, 1] [消费者0]消费商品1 列表剩余:[0] 列表商品:[0] [消费者0]消费商品0 列表剩余:[] [生产者0]生产商品2 列表商品:[2] [消费者1]消费商品2 列表剩余:[] [生产者0]生产商品3 [生产者1]生产商品0 [生产者0]生产商品4 列表商品:[3, 0, 4] [消费者1]消费商品4 列表剩余:[3, 0] [生产者1]生产商品1 [生产者1]生产商品2 [生产者1]生产商品3 [生产者1]生产商品4 列表商品:[3, 0, 1, 2, 3, 4] [消费者2]消费商品4 列表剩余:[3, 0, 1, 2, 3] 列表商品:[3, 0, 1, 2, 3] [消费者0]消费商品3 列表剩余:[3, 0, 1, 2] 列表商品:[3, 0, 1, 2] [消费者1]消费商品2 列表剩余:[3, 0, 1] 列表商品:[3, 0, 1] [消费者3]消费商品1 列表剩余:[3, 0] 列表商品:[3, 0] [消费者3]消费商品0 列表剩余:[3] 列表商品:[3] [消费者3]消费商品3 列表剩余:[]通知方法: notify() :发出资源可用的信号,唤醒任意一条因 wait()阻塞的进程 notifyAll() :发出资源可用信号,唤醒所有因wait()阻塞的进程 2.2.5.线程同步~信号量Semaphore(互斥锁的高级版)¶记得当时在分析multiprocessing.Queue源码的时候,有提到过(点我回顾) 同进程的一样,semaphore管理一个内置的计数器,每当调用acquire()时内置函数-1,每当调用release()时内置函数+1 通俗讲就是:在互斥锁的基础上封装了下,实现一定程度的并行 举个例子,以前使用互斥锁的时候:(厕所就一个坑位,必须等里面的人出来才能让另一个人上厕所) 使用信号量之后:厕所坑位增加到5个(自己指定),这样可以5个人一起上厕所了==>实现了一定程度的并发 举个例子:(Python在语法这点特别爽,不用你记太多异同,功能差不多基本上代码也就差不多) from time import sleepfrom multiprocessing.dummy import Pool as ThreadPool, Semaphoresem = Semaphore(5) # 限制最大连接数为5def goto_wc(i): global sem with sem: print(f"[线程{i}]上厕所") sleep(0.1)def main(): p = ThreadPool() p.map_async(goto_wc, range(50)) p.close() p.join()if __name__ == '__main__': main()输出: 可能看了上节回顾的会疑惑:源码里面明明是BoundedSemaphore,搞啥呢? 其实BoundedSemaphore就比Semaphore多了个在调用release()时检查计数器的值是否超过了计数器的初始值,如果超过了将抛出一个异常 以上一个案例说事:你换成BoundedSemaphore和上面效果一样==>sem = BoundedSemaphore(5) 锁专题扩展¶1.加锁机制¶ 在多线程程序中,死锁问题很大一部分是由于线程同时获取多个锁造成的,eg:一个线程获取了第一个锁,然后在获取第二个锁的 时候发生阻塞,那么这个线程就可能阻塞其他线程的执行,从而导致整个程序假死。 解决死锁问题的一种方案是为程序中的每一个锁分配一个唯一的id,然后只允许按照升序规则来使用多个锁,当时举了个小明小张转账的简单例子,来避免死锁,这次咱们再看一个案例:(这个规则使用上下文管理器非常简单) 先看看源码,咱们怎么使用: # 装饰器方法def contextmanager(func): """ 方法格式 @contextmanager def some_generator(): try: yield finally: 然后就可以直接使用with托管了 with some_generator() as : """ @wraps(func) def helper(*args, **kwds): return _GeneratorContextManager(func, args, kwds) return helper翻译成代码就是这样了:(简化) from contextlib import contextmanager # 引入上下文管理器@contextmanagerdef lock_manager(*args): # 先排个序(按照id排序) args = sorted(args, key=lambda x: id(x)) try: for lock in args: lock.acquire() yield finally: # 先释放最后加的锁(倒序释放) for lock in reversed(args): lock.release()基础忘记了可以点我(lambda) 以上面小明小张转账案例为例子:(不用再管锁顺序之类的了,直接全部丢进去:with lock_manager(...)) from contextlib import contextmanager # 引入上下文管理器from multiprocessing.dummy import Pool as ThreadPool, Lock@contextmanagerdef lock_manager(*args): # 先排个序(按照id排序) args = sorted(args, key=lambda x: id(x)) try: for lock in args: lock.acquire() yield finally: # 先释放最后加的锁(倒序释放) for lock in reversed(args): lock.release()xiaoming = 5000xiaozhang = 8000m_lock = Lock() # 小明的锁z_lock = Lock() # 小张的锁# 小明转账1000给小张def a_to_b(): global xiaoming global xiaozhang global m_lock global z_lock print(f"[转账前]小明{xiaoming},小张{xiaozhang}") with lock_manager(m_lock, z_lock): xiaoming -= 1000 xiaozhang += 1000 print(f"[转账后]小明{xiaoming},小张{xiaozhang}")# 小张转账1000给小明def b_to_a(): global xiaoming global xiaozhang global m_lock global z_lock print(f"[转账前]小明{xiaoming},小张{xiaozhang}") with lock_manager(m_lock, z_lock): xiaozhang -= 1000 xiaoming += 1000 print(f"[转账后]小明{xiaoming},小张{xiaozhang}")def main(): print(f"[互刷之前]小明{xiaoming},小张{xiaozhang}") p = ThreadPool() for _ in range(5): p.apply_async(a_to_b) p.apply_async(b_to_a) p.close() p.join() print(f"[互刷之后]小明{xiaoming},小张{xiaozhang}")if __name__ == '__main__': main()输出: [互刷之前]小明5000,小张8000 [转账前]小明5000,小张8000 [转账前]小明5000,小张8000 [转账后]小明4000,小张9000 [转账前]小明5000,小张8000 [转账后]小明5000,小张8000 [转账前]小明5000,小张8000 [转账前]小明4000,小张9000 [转账后]小明4000,小张9000 [转账后]小明5000,小张8000 [转账前]小明5000,小张8000 [转账后]小明4000,小张9000 [转账前]小明4000,小张9000 [转账前]小明4000,小张9000 [转账后]小明5000,小张8000 [转账前]小明5000,小张8000 [转账后]小明4000,小张9000 [转账后]小明5000,小张8000 [转账前]小明5000,小张8000 [转账后]小明4000,小张9000 [转账后]小明5000,小张8000 [互刷之后]小明5000,小张8000再来个验证,在他们互刷的过程中,小潘还了1000元给小明 from time import sleepfrom contextlib import contextmanager # 引入上下文管理器from multiprocessing.dummy import Pool as ThreadPool, Lock@contextmanagerdef lock_manager(*args): # 先排个序(按照id排序) args = sorted(args, key=lambda x: id(x)) try: for lock in args: lock.acquire() yield finally: # 先释放最后加的锁(倒序释放) for lock in reversed(args): lock.release()xiaopan = 9000xiaoming = 5000xiaozhang = 8000m_lock = Lock() # 小明的锁z_lock = Lock() # 小张的锁p_lock = Lock() # 小潘的锁# 小明转账1000给小张def a_to_b(): global xiaoming global xiaozhang global m_lock global z_lock print(f"[转账前]小明{xiaoming},小张{xiaozhang}") with lock_manager(m_lock, z_lock): xiaoming -= 1000 xiaozhang += 1000 print(f"[转账后]小明{xiaoming},小张{xiaozhang}")# 小张转账1000给小明def b_to_a(): global xiaoming global xiaozhang global m_lock global z_lock print(f"[转账前]小明{xiaoming},小张{xiaozhang}") with lock_manager(m_lock, z_lock): xiaozhang -= 1000 xiaoming += 1000 print(f"[转账后]小明{xiaoming},小张{xiaozhang}")# 小潘还1000给小明def c_to_a(): global xiaoming global xiaopan global m_lock global p_lock print(f"[转账前]小明{xiaoming},小潘{xiaopan}") with lock_manager(m_lock, p_lock): xiaopan -= 1000 xiaoming += 1000 print(f"[转账后]小明{xiaoming},小潘{xiaopan}")def main(): print(f"[互刷之前]小明{xiaoming},小张{xiaozhang},小潘{xiaopan}") p = ThreadPool() for _ in range(5): p.apply_async(a_to_b) # 在他们互刷的过程中,小潘还了1000元给小明 if _ == 3: p.apply_async(c_to_a) p.apply_async(b_to_a) p.close() p.join() print(f"[互刷之后]小明{xiaoming},小张{xiaozhang},小潘{xiaopan}")if __name__ == '__main__': main()输出: [互刷之前]小明5000,小张8000,小潘9000 [转账前]小明5000,小张8000 [转账前]小明5000,小张8000 [转账后]小明4000,小张9000 [转账前]小明5000,小张8000 [转账前]小明4000,小张9000 [转账后]小明5000,小张8000 [转账前]小明5000,小张8000 [转账后]小明4000,小张9000 [转账后]小明5000,小张8000 [转账前]小明5000,小张8000 [转账后]小明4000,小张9000 [转账前]小明4000,小张9000 [转账前]小明4000,小潘9000 # 注意下这个 [转账后]小明5000,小张8000 [转账前]小明5000,小张8000 [转账后]小明4000,小张9000 [转账后]小明5000,小潘8000 # 注意下这个 [转账前]小明5000,小张9000 [转账后]小明6000,小张8000 [转账后]小明5000,小张9000 [转账前]小明6000,小张8000 [转账后]小明6000,小张8000 [互刷之后]小明6000,小张8000,小潘8000上下文管理器进一步完善¶from contextlib import contextmanagerfrom multiprocessing.dummy import threading # or import threading# ThreadLocal 下节会说_local = threading.local()@contextmanagerdef acquire(*args): # 以id将锁进行排序 args = sorted(args, key=lambda x: id(x)) # 确保不违反以前获取的锁顺序 acquired = getattr(_local, 'acquired', []) if acquired and max(id(lock) for lock in acquired) >= id(args[0]): raise RuntimeError('锁顺序有问题') # 获取所有锁 acquired.extend(args) _local.acquired = acquired # ThreadLocal:每个线程独享acquired # 固定格式 try: for lock in args: lock.acquire() yield finally: # 逆向释放锁资源 for lock in reversed(args): lock.release() # 把释放掉的锁给删了 del acquired[-len(args):]2.哲学家吃面¶先看看场景:五个外国哲学家到中国来吃饭了,因为不了解行情,每个人只拿了一双筷子,然后点了一大份的面。碍于面子,他们不想再去拿筷子了,于是就想通过脑子来解决这个问题。 每个哲学家吃面都是需要两只筷子的,这样问题就来了:(只能拿自己两手边的筷子) 如果大家都是先拿自己筷子,再去抢别人的筷子,那么就都等着饿死了(死锁) 如果有一个人打破这个常规,先拿别人的筷子再拿自己的,那么肯定有一个人可以吃到面了 5个筷子,意味着最好的情况 ==> 同一时刻有2人在吃(0人,1人,2人) 把现实问题转换成代码就是: 哲学家--线程 筷子--资源(几个资源对应几把锁) 吃完一口面就放下筷子--lock的释放 有了上面基础这个就简单了,使用死锁避免机制解决哲学家就餐问题的实现:(不用再操心锁顺序了) from contextlib import contextmanager # 引入上下文管理器from multiprocessing.dummy import Pool as ThreadPool, Lock, current_process as current_thread# 使用简化版,便于你们理解@contextmanagerdef lock_manager(*args): # 先排个序(按照id排序) args = sorted(args, key=lambda x: id(x)) try: # 依次加锁 for lock in args: lock.acquire() yield finally: # 先释放最后加的锁(倒序释放) for lock in reversed(args): lock.release()#########################################def eat(l_lock, r_lock): while True: with lock_manager(l_lock, r_lock): # 获取当前线程的名字 print(f"{current_thread().name},正在吃面") sleep(0.5)def main(): resource = 5 # 5个筷子,5个哲学家 locks = [Lock() for i in range(resource)] # 几个资源几个锁 p = ThreadPool(resource) # 让线程池里面有5个线程(默认是cup核数) for i in range(resource): # 抢左手筷子(locks[i])和右手的筷子(locks[(i + 1) % resource]) # 举个例子更清楚:i=0 ==> 0,1;i=4 ==> 4,0 p.apply_async(eat, args=(locks[i], locks[(i + 1) % resource])) p.close() p.join()if __name__ == '__main__': main()输出图示: PS:这个一般都是操作系统的算法,了解下就可以了,上面哲学家吃面用的更多一点(欢迎投稿~) 我们可以把操作系统看作是银行家,操作系统管理的资源相当于银行家管理的资金,进程向操作系统请求分配资源相当于用户向银行家贷款。 为保证资金的安全,银行家规定: 当一个顾客对资金的最大需求量不超过银行家现有的资金时就可接纳该顾客; 顾客可以分期贷款,但贷款的总数不能超过最大需求量; 当银行家现有的资金不能满足顾客尚需的贷款数额时,对顾客的贷款可推迟支付,但总能使顾客在有限的时间里得到贷款; 当顾客得到所需的全部资金后,一定能在有限的时间里归还所有的资金. 操作系统按照银行家制定的规则为进程分配资源,当进程首次申请资源时,要测试该进程对资源的最大需求量,如果系统现存的资源可以满足它的最大需求量则按当前的申请量分配资源,否则就推迟分配。当进程在执行中继续申请资源时,先测试该进程本次申请的资源数是否超过了该资源所剩余的总量。若超过则拒绝分配资源,若能满足则按当前的申请量分配资源,否则也要推迟分配。 通俗讲就是:当一个进程申请使用资源的时候,银行家算法通过先试探分配给该进程资源,然后通过安全性算法判断分配后的系统是否处于安全状态,若不安全则试探分配作废,让该进程继续等待。 参考链接: https://www.cnblogs.com/chuxiuhong/p/6103928.html https://www.cnblogs.com/Lynn-Zhang/p/5672080.html https://blog.csdn.net/qq_33414271/article/details/80245715 https://blog.csdn.net/qq_37315403/article/details/821797072.读写锁¶Python里面没找到读写锁,这个应用场景也是有的,先简单说说这个概念,你可以结合RLock实现读写锁(了解下,用到再研究) 读写锁(一把锁): 读共享:A加读锁,B、C想要加读锁==>成功(并行操作) 写独占:A加写锁,B、C想要读(写)==>阻塞等 读写不能同时(写优先级高):A读,B要写,C要读,D要写==>A读了,B在写,C等B写完读,D等C读完写(读写不能同时进行) 扩展参考: http://xiaorui.cc/?p=2384 https://www.jb51.net/article/82999.htm https://blog.csdn.net/11b202/article/details/11478635 https://blog.csdn.net/vcbin/article/details/51181121 扩展:线程安全¶ 上次说了锁相关,把问题稍微汇聚提炼一下~重点在思想,语言无差别 1.安全终止线程¶正常执行线程任务没什么好说的,可以通过isAlive判断当前线程状态,对于耗时操作可以设置超时时间t.join(timeout=1)+重试机制 但是后台线程Thread(daemon=True)就没那么好控制了:这些线程会在主线程终止时自动销毁。除了如上所示的两个操作,并没有太多可以对线程做的事情(无法结束一个线程,无法给它发送信号,无法调整它的调度,也无法执行其他高级操作) 通用:寻常线程¶比如说,如果你需要在不终止主线程的情况下杀死线程,那么这个线程就不能通过daemon的方式了,必须通过编程在某个特定点轮询来退出: from time import sleepfrom multiprocessing.dummy import threadingclass MyThread(threading.Thread): def __init__(self): self.__running = True super().__init__() def terminate(self): self.__running = False def run(self): # 轮询方式必须根据业务来,不然没有意义 while self.__running: print("do something") sleep(2)def main(): t = MyThread() t.start() t.terminate() # 调用的时候可以通过`terminate`来结束线程 t.join() # t.join(timeout=1) # 超时时间 print("over")if __name__ == '__main__': main()输出:(再提醒一下,轮循必须根据业务来,不管是重试机制还是其他,这边只是举个例子) do something over上面这种方式,比较好理解,但是比较依赖threading.Thread,项目里面一般这么改下: from time import sleepfrom multiprocessing.dummy import threadingclass ShutdownTask(object): def __init__(self): self.__running = True def terminate(self): self.__running = False def run(self): # 轮询方式必须根据业务来,不然没有意义 while self.__running: print("do something") sleep(2)def main(): task = ShutdownTask() t = threading.Thread(target=task.run) t.start() task.terminate() # 结束线程 t.join() print("over")if __name__ == '__main__': main()输出:(ShutdownTask就解耦了,不依赖threading库了,你放在进程中使用也没事了) do something over通用:阻塞线程¶是不是心想着现在都妥妥的了?但是遗憾的是~如果遇到了IO阻塞的情况,轮循形同虚设,这时候就需要超时时间来解决了: join(timeout)是一种方式 socket的超时机制也是一种方式(后面会探讨) 伪代码实现:(加上重试机制更完善) class IOTask: def __init__(self): self.__running = True def terminate(self): self.__running = False def run(self, socket): socket.settimeout(3) # 设置超时时间 while self.__running: try: print("正在忙.....") socket.recv(8192) sleep(1) break except Exception: print("超时处理") break由于全局解释锁(GIL)的原因,Python 的线程被限制到同一时刻只允许一个线程执行这样一个执行模型。所以,Python 的线程更适用于处理I/O和其他需要并发执行的阻塞操作(比如等待I/O、等待从数据库获取数据等等),而不是需要多处理器并行的计算密集型任务。【这也是为什么我说Python和其他语言并发编程的重点不一样:进程+协程】 特有:进程安全退出¶Python进程Process可以通过:terminate() or signal的方式终止:(点我回顾) terminate联合signal进行退出前处理: from time import sleepfrom signal import signal, SIGTERMfrom multiprocessing import Process# 可以释放锁、记录日记之类的操作def save_data(signalnum, frame): print(f"[退出前处理]signalnum:{signalnum},frame:{frame}") exit(0)def test(): # 信号处理 signal(SIGTERM, save_data) print("subProcess start") sleep(2) print("subProcess over")def main(): p = Process(target=test) p.start() sleep(1) p.terminate() # 进程结束 p.join() print("mainProcess over")if __name__ == '__main__': main()输出: subProcess start[退出前处理]signalnum:15,frame:mainProcess over还有一种方式,通过进程间状态共享(点我回顾),实现优雅的退出子进程 2.线程共享安全¶这块上面说很多了,再介绍几种: CAS原子类(Java比较常用) Thread Local(常用场景:存各种的连接池) Lock,互斥锁,可重入锁(递归锁),信号量,条件变量(上面都在说这些) 在多线程环境下,每个线程都有自己的数据,想要互不干扰又不想定义成局部变量传来传去,怎么办? 一开始是这么解决的: from multiprocessing.dummy import threadingglobal_dict = {}def task1(): # 根据当前线程查找: global_dict[threading.current_thread()] = 10 global_dict[threading.current_thread()] += 10def task2(): # 根据当前线程查找: global_dict[threading.current_thread()] = 10 global_dict[threading.current_thread()] -= 10def main(): t1 = threading.Thread(target=task1) t2 = threading.Thread(target=task2) t1.start() t2.start() t1.join() t2.join() print(global_dict)if __name__ == '__main__': main()但这么搞也很麻烦,于是就有了ThreadLocal: from multiprocessing.dummy import threadingglobal_local = threading.local()def show_name(): print(f"[{threading.current_thread().name}]{global_local.name}")def task1(): global_local.name = "小明" show_name()def task2(): global_local.name = "小张" show_name()def main(): t1 = threading.Thread(target=task1) t2 = threading.Thread(target=task2) t1.start() t2.start() t1.join() t2.join()if __name__ == '__main__': main()输出:(同样存的是name属性,不同线程间互不影响) [Thread-1]小明 [Thread-2]小张导航¶再来谈谈常用的两种死锁解决思路:(这次不仅仅局限在Python了) "顺序锁" tryLock 说说顺序锁的算法:hash Sort(3种情况),先看看几种hash的对比吧: In [1]: %timefrom multiprocessing.dummy import Lockm_lock = Lock()z_lock = Lock()print(f"是否相等:{m_lock==z_lock}\n{m_lock}\n{z_lock}") # 地址不一样CPU times: user 5 µs, sys: 0 ns, total: 5 µs Wall time: 10.3 µs 是否相等:False In [2]: %timem_code = hash(m_lock)z_code = hash(z_lock)print(f"是否相等:{m_code==z_code}\n{m_code}\n{z_code}") # 值一样CPU times: user 3 µs, sys: 0 ns, total: 3 µs Wall time: 5.96 µs 是否相等:False -9223363285699470954 -9223363285696256091 In [3]: %timefrom hashlib import sha1# Java可以使用:identityhashcodem_code = sha1(str(m_lock).encode("utf-8")).hexdigest()z_code = sha1(str(z_code).encode("utf-8")).hexdigest()print(f"是否相等:{m_code==z_code}\n{m_code}\n{z_code}") # 不相等CPU times: user 4 µs, sys: 1 µs, total: 5 µs Wall time: 8.58 µs 是否相等:False c7b3667aab3e5df84652c5a182dffa6fee3653d0 146e3f223150ed48f1d813dcef3f158fce350487 In [4]: %timem_code = id(m_lock)z_code = id(z_lock)print(f"是否相等:{m_code==z_code}\n{m_code}\n{z_code}") # 不相等CPU times: user 3 µs, sys: 0 ns, total: 3 µs Wall time: 5.48 µs 是否相等:False 140018484877672 140018536315480 动态死锁¶ 如果是一般的顺序死锁,那么程序代码改改逻辑基本上就可以避免了。比如调试的时候就知晓,或者借助类似于jstack or 开发工具查看: 怕就怕在动态上==>举个例子:(还是小明小张互刷的案例) 有人实践后很多疑问,说明明我就按照顺序加锁了啊,先加转出账号,再加锁转入账号? 其实...换位思考就懂了==>伪代码 def transfer(p_from, p_to, money): with p_from.lock: p_from.money -= money ...... with p_to.lock: p_to += money这个虽然按照了所谓的顺序,但是转帐人其实在变,也就变成了动态的,所以也会出现死锁: from time import sleepfrom multiprocessing.dummy import Pool as ThreadPool, Lockclass People(object): def __init__(self, name, money=5000): self.name = name self.lock = Lock() self.money = money # 设置一个初始金额def transfer(p_from, p_to, money): with p_from.lock: p_from.money -= money sleep(1) # 模拟网络延迟 with p_to.lock: p_to += moneydef main(): xiaoming = People("小明") xiaozhang = People("小张") print(f"[互刷前]小明:{xiaoming.money},小张:{xiaozhang.money}") p = ThreadPool() p.apply_async(transfer, args=(xiaoming, xiaozhang, 1000)) p.apply_async(transfer, args=(xiaozhang, xiaoming, 1000)) p.close() p.join() print(f"[互刷后]小明:{xiaoming.money},小张:{xiaozhang.money}")if __name__ == '__main__': main()输出:(死锁了,联想哲学家吃面~每个人先拿自己的筷子再抢人的筷子) [互刷前]小明:5000,小张:5000解决方案~伪代码思路: def transfer(cls, p_from, p_to, money): """p_from:谁转账,p_to:转给谁,money:转多少""" from_hash = get_hash(p_from) to_hash = get_hash(p_to) # 规定:谁大先锁谁 if from_hash > to_hash: with p_from.lock: p_from.money -= money sleep(1) # 模拟网络延迟 with p_to.lock: p_to.money += money elif from_hash to_hash: print("from_hash > to_hash") with p_from.lock: p_from.money -= money sleep(1) # 模拟网络延迟 with p_to.lock: p_to.money += money elif from_hash 1000 from_hash 1000 from:小明to小张=>1000 from_hash > to_hash from_hash 1000 from_hash 1000 from:小明to小张=>1000 from_hash > to_hash from_hash 1000 from_hash > to_hash [互刷后]小明:6000,小张:5000,小潘4000
Python上下文管理器我就不说了,上面说过了,思路和“顺序锁”基本一样: from contextlib import contextmanagerfrom multiprocessing.dummy import threading # or import threading_local = threading.local()@contextmanagerdef acquire(*args): # 以id将锁进行排序 args = sorted(args, key=lambda x: id(x)) # 确保不违反以前获取的锁顺序 acquired = getattr(_local, 'acquired', []) if acquired and max(id(lock) for lock in acquired) >= id(args[0]): raise RuntimeError('锁顺序有问题') # 获取所有锁 acquired.extend(args) _local.acquired = acquired # ThreadLocal:每个线程独享acquired # 固定格式 try: for lock in args: lock.acquire() yield finally: # 逆向释放锁资源 for lock in reversed(args): lock.release() # 把释放掉的锁给删了 del acquired[-len(args):]活锁¶大家都听说过死锁deadlock,但是很少有人听说过活锁livelock。活锁主要由两个线程过度谦让造成,两个线程都想让对方先干话,结果反而都无法继续执行下去。因为两个线程都在活跃状态,故称活锁。 trylock¶trylock可以解决死锁问题,但是用不好也会出现少见的活锁问题: from time import sleepfrom random import randomfrom multiprocessing.dummy import Pool as ThreadPool, Lockclass People(object): def __init__(self, name, money=5000): self.name = name self.lock = Lock() # 非阻塞等 self.money = money # 设置一个初始金额def transfer(p_from, p_to, money): flag = True while flag: # 尝试获取p_from.lock if p_from.lock.acquire(False): # 非阻塞 try: sleep(1) # 模拟网络延迟 # 尝试获取p_to.lock if p_to.lock.acquire(False): try: p_from.money -= money p_to.money += money flag = False finally: print("p_to release") p_to.lock.release() # 释放锁 finally: p_from.lock.release() # 释放锁 sleep(random()) # 随机睡[0,1)sdef main(): xiaoming = People("小明") xiaozhang = People("小张") xiaopan = People("小潘") print(f"[互刷前]小明:{xiaoming.money},小张:{xiaozhang.money},小潘:{xiaopan.money}") p = ThreadPool() for i in range(3): p.apply_async(transfer, args=(xiaoming, xiaozhang, 1000)) if i == 1: p.apply_async(transfer, args=(xiaopan, xiaoming, 1000)) p.apply_async(transfer, args=(xiaozhang, xiaoming, 1000)) p.close() p.join() print(f"[互刷后]小明:{xiaoming.money},小张:{xiaozhang.money},小潘:{xiaopan.money}")if __name__ == '__main__': main()输出:(没有sleep(random()) # 随机睡[0,1)s就是一个活锁了) [互刷前]小明:5000,小张:5000,小潘:5000 p_to release p_to release p_to release p_to release p_to release p_to release [互刷后]小明:6000,小张:5000,小潘:4000
可以思考一下,为什么trylock的时候p_from.money -= money和p_to.money += money都要放在code最里面 参考链接: 守护线程参考:https://www.cnblogs.com/brolanda/p/4709947.html Posix Thread:https://www.cnblogs.com/randyniu/p/9189112.html 一句话实现并行:http://chriskiehl.com/article/parallelism-in-one-line 进程与线程的一个简单解释:http://www.ruanyifeng.com/blog/2013/04/processes_and_threads.html 线程分离方面的参考: http://python.su/forum/topic/20403/ https://stackoverflow.com/questions/14175016/python-pthread-detach-analog https://stackoverflow.com/questions/11904848/what-is-the-difference-between-a-detached-thread-and-a-daemon-thread 线程锁参考: https://www.cnblogs.com/nuomin/p/7899675.html https://blog.csdn.net/alina_catty/article/details/78792085 https://mozillazg.com/2016/09/python-threading-multiprocessing-logging-equal-deadlock.html 死锁调试参考: https://blog.alswl.com/2013/11/python-gdb https://wiki.python.org/moin/DebuggingWithGdb http://www.blogjava.net/stone2083/archive/2013/08/19/403028.html https://stackoverflow.com/questions/1289124/python-equivalent-of-jstack https://mozillazg.com/2016/09/python-threading-multiprocessing-logging-equal-deadlock.html https://stackoverflow.com/questions/132058/showing-the-stack-trace-from-a-running-python-application 使用ctypes强行杀掉线程:https://blog.csdn.net/vinsuan1993/article/details/78158589 老外对杀死子线程的探讨: https://stackoverflow.com/questions/323972/is-there-any-way-to-kill-a-thread-in-python作者:毒逆天 出处:https://www.cnblogs.com/dotnetcrazy/p/9528315.html 本文版权归作者和博客园共有。欢迎转载,但必须保留此段声明,且在文章页面明显位置给出原文连接! 打开App,阅读手记 |







【本文地址】